Argoverse基线模型分析
数据集探索
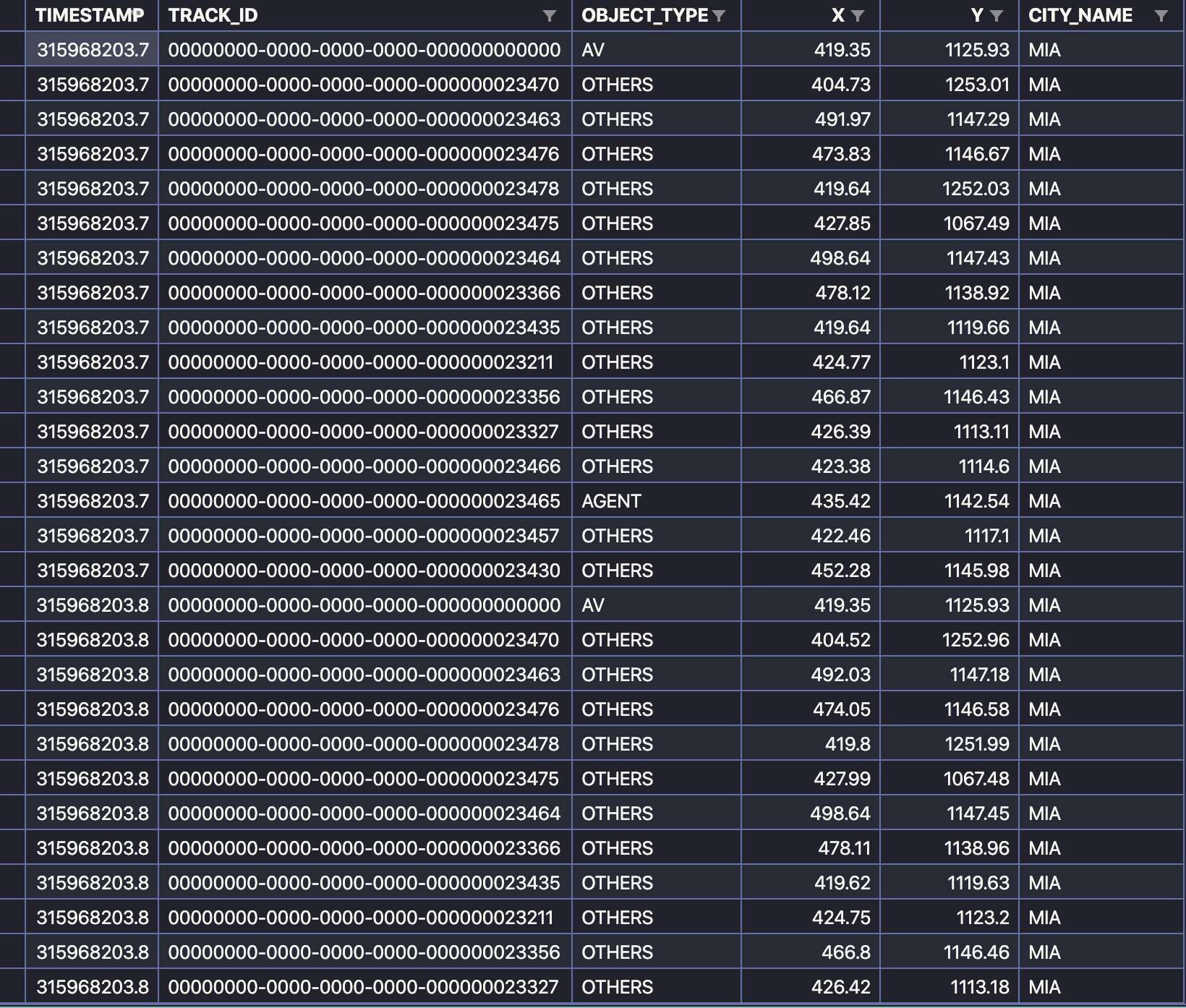
下图是某一个sequence的部分截图,可以看到一个sequence包含了时间信息、车辆ID信息、类型、绝对坐标、以及城市,这里时间是以秒为单位的,然后采集的数据是10HZ,因此一个sequence包含了每个跟踪车辆的50行信息,这个sequence中有16个跟踪车辆,所以一共就有800行。其中车辆类型分成AV、OTHERS、AGENT。这里AV就是收集数据的车辆,AGENT是我们感兴趣的需要预测轨迹的目标车辆,OTHERS是可以用来辅助预测AGENT轨迹的相关车辆。
基线模型介绍
Argoverse在公开数据集的同时也给出了多种比较简单的基线模型,这些基线模型分别是:
-
Constant Velocity:
即计算2秒观测时间内感兴趣车辆的平均速度,然后用这个速度作为之后预测的车辆速度,并计算相应的坐标。
-
LSTM的几种变体
-
LSTM Encoder-Decoder model
这个是google提出的,是序列预测领域非常经典的用于多输入多输出任务的模型。输入为$(x^t_i, y^t_i), t = {1, \dots, T_{obs}}$,输出为$(x^t_i, y^t_i), t = {T_{obs+1}, \dots, T_{pred}}$
-
LSTM + social
和上一个基本一致,只不过输入的信息多了一个social context,即和前后车辆的距离。
-
LSTM + map(prior) 1-G, n-C
这个模型采用的输入不是绝对坐标,而是曲线坐标,即距离中心线的偏移距离以及车辆和车道起始点的距离,之所以叫做 LSTM + map(prior) ,是因为这些坐标信息都需要高精度地图才能计算。另外,1-G, n-C的含义是沿每一个车道中心线输出一个预测。
-
-
NN的几种变体
-
NN
最近邻算法,就是简单的相似查询了,查找和当前的观测轨迹最为接近的几条轨迹然后输出。
-
NN + map(prune)
这个是多了一个评判标准,即通过地图来判断查询出来的轨迹是否偏离了可行驶区域,是的话就将其去掉。
-
NN + map(prior) m-G, n-C
这个是采用曲线坐标,然后沿n个道路中心线做预测,每个中心线预测m个轨迹,所以每次预测一共会有m * n的轨迹。
-
NN + map(prior) 1-G, n-C
和上面的相似,只是每个中心线只预测1条轨迹。
-
实验分析
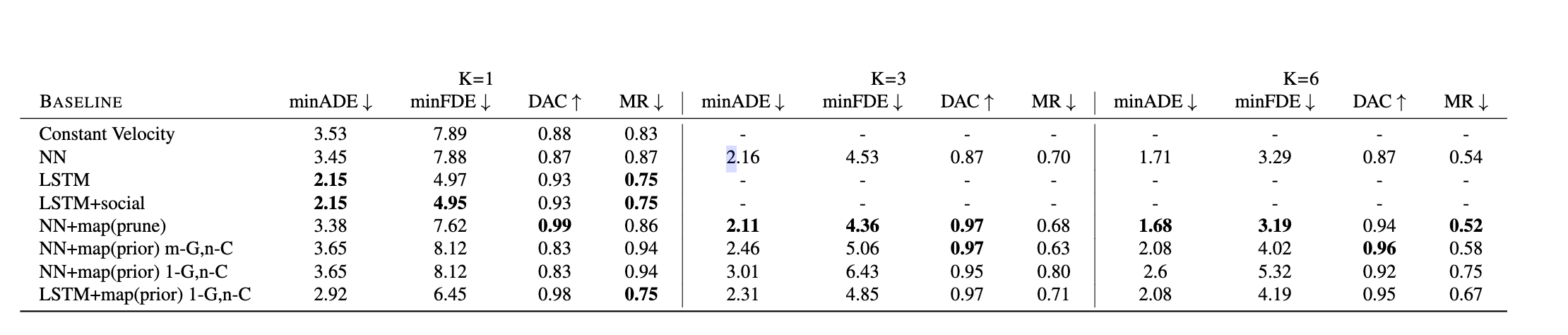
上图是上述模型的测试结果,作者做了一个比较详解的分析,这里就不展开了。
比较关键的几个点在于:
-
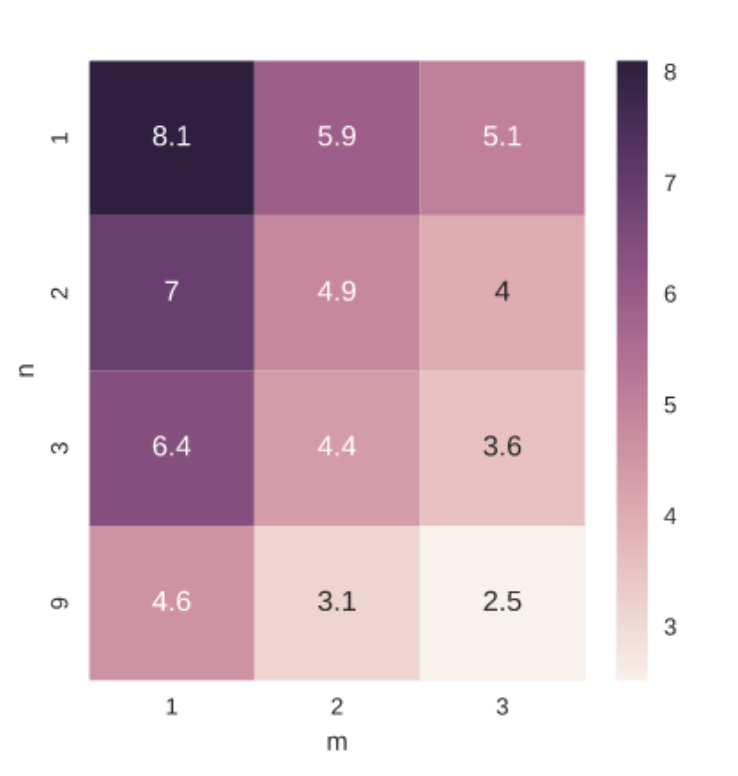
LSTM在曲线坐标下的泛化性要好于NN
-
采用曲线坐标总是能提供一个更好的DAC(Drivable Area Compliance)
-
另外m和n的选择上,作者用控制变量法来观察,发现增加m的效果要好于增加n的效果,即在较少的参考中心线下做更多的预测要好于在较多的参考中心线下做较少的预测。