《VectorNet: Encoding HD Maps and Agent Dynamics from Vectorized Representation》阅读笔记
本文对Waymo近期提出的Vectornet做了一个较为详细的分析。
论文摘要
因为道路组件的表示复杂性和交互性,包括移动目标(例如行人和车辆)和道路上下文信息(例如车道和红绿灯),动态多代理系统的行为预测是自动驾驶汽车的一个重要问题。本文介绍VectorNet,一个分层图神经网络(GNN)。首先,其用矢量表示各个道路组件的空间局部性,然后对所有组件之间的高级交互进行建模。最近的方法将移动目标和道路上下文信息的轨迹呈现为鸟瞰图像,并用卷积神经网络(ConvNets)进行编码。与其相反,该文方法以矢量形式进行操作。通过对矢量化的高清(HD)地图和代理轨迹进行操作,避免了有损渲染和计算密集型ConvNet编码的步骤。为进一步增强VectorNet在学习上下文特征方面的能力,文章提出了一项新辅助任务,根据上下文恢复随机掩盖的地图实体和代理轨迹。根据内部行为预测基准和最近发布的Argoverse预测数据集,对对VectorNet进行了评估。该方法在两个基准均达到了与渲染方法相同或更好的性能,同时节省了70%以上的模型参数,而且FLOPs减少了一个数量级。它在Argoverse数据集的表现也超越了现有技术。
引自知乎专栏1
详解
架构
下图显示了传统的图像渲染表征和vectornet2的矢量表征之间的区别:
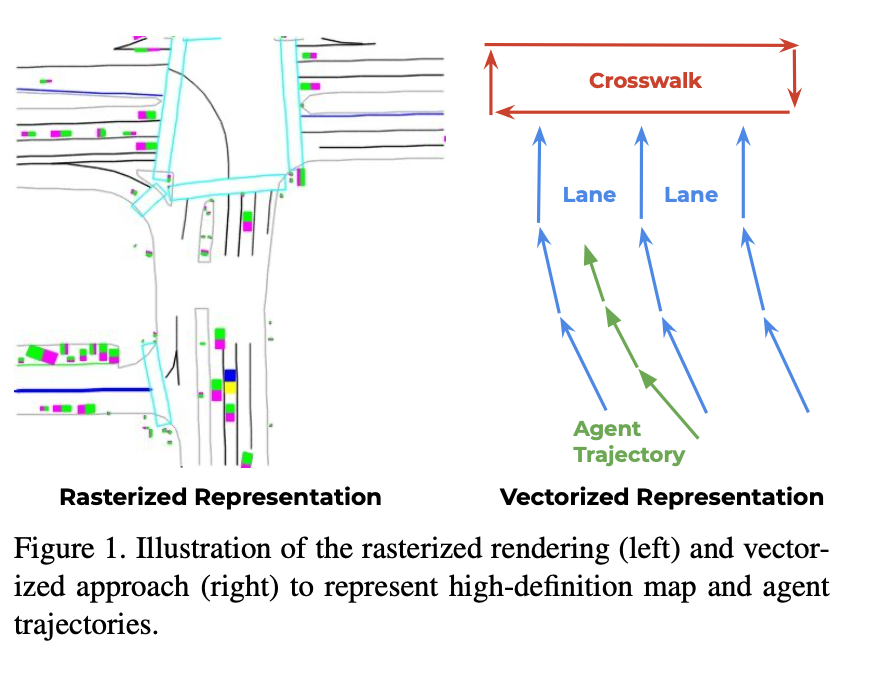
具体来说,车道以及岔路口这类的静态物体在高精度地图上是用样条曲线来表示的(splines),因此为了将其转换为向量表示,是先选择一个起点和方向,在相同的空间距离上均匀地从样条曲线中采样关键点,然后将相邻关键点依次连接组成向量。
而车辆轨迹这种则是在时间上采样,从t = 0开始以固定的时间间隔(0.1秒)对关键点进行采样,然后将它们连接从而组成向量。
然后这样的每一个向量都会成为图神经网络中的一个节点,由于一个物体包含了多个节点,这里自然地将同属于一个对象的这些节点组成一个子图,然后这些对象组成的子图再经过Global interaction graph(单层的GNN)相互连接,这就是整体的网络架构,如下图所示。
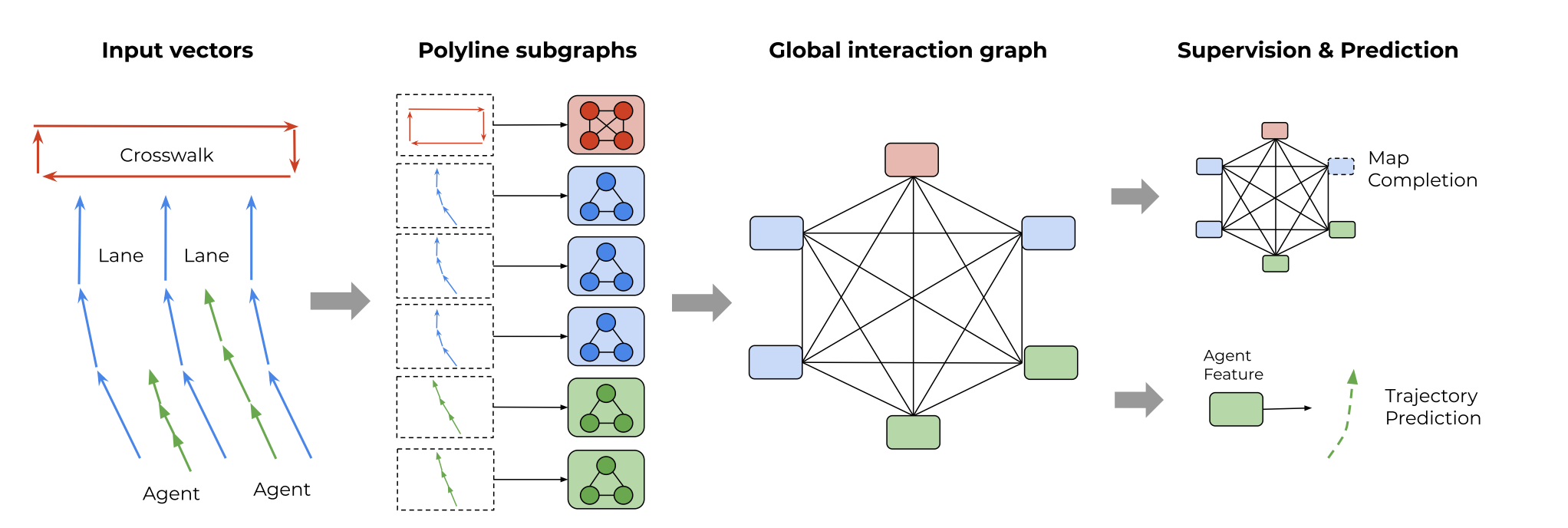
这里的细节问题是:各个节点的属性是什么?
论文中指出,每个节点(向量)包含4个主要属性,即起始点、终点、附加属性,以及每个节点所属于对象的编号。这里附加属性包括的东西比较多,例如对象类型,轨迹的时间戳,道路类型或车道的速度限制。
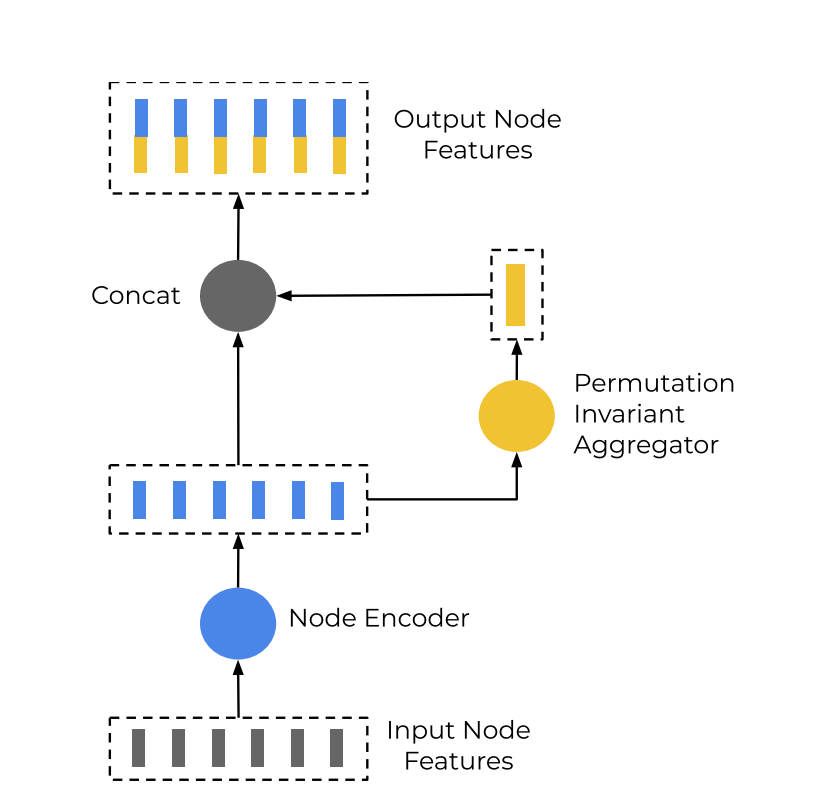
另一个细节在于一个子图中所有节点是怎么聚合的,如下图所示,基本流程就是将这些节点的特征通过一个用单层MLP做的Node Encoder,然后再将所有特征聚合起来,最后子图的输出就是聚合特征和MLP输出的特征concat一下。
训练
这里规定了两种类型的损失,一个是正常的预测损失,即预测出来的轨迹和真实轨迹的差别,另外一个是作者提出的graph completion loss,即随机地将网络的一些节点特征去掉,让网络根据周围节点的信息来预测当前节点的信息,intuition是想要让网络更好地捕捉到agents的行动和周围环境的关系。